I was somewhat surprised by several comments on social media in response to my last post, The War Against Machine Translation. Many of the comments spoke out in defense of machine translation (MT). In retrospect, some of the claims I made in my first post were a little far reaching. I’d like to address some of the points made in response to that post, and also clarify and moderate some of the initial claims I made.
I also want to preface this follow-up by stating that I am an avid proponent of Computer Assisted Language Learning (CALL). I have spent the last few years developing a website full of activities and tools for teachers and learners of English as a Foreign Language. However, I believe that anything that can be accurately classed as CALL must by definition assist the learning of a language.

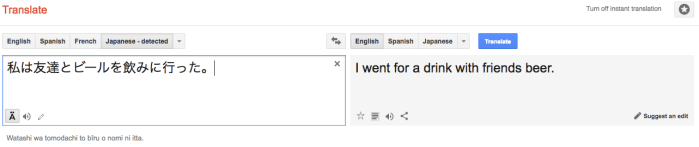
Learning technology should never completely replace the learner. Unfortunately, the way many students view and use the output of MT is as a complete replacement for their own work. In some cases, entire reports are written in L1, pasted into an MT tool, and then the output is submitted as the student’s “own work”. It would be very difficult to say that the students in these cases have learned anything about English. In many cases students fail to even read the result of MT before submitting it, containing as it does so many basic grammatical errors (especially with Japanese to English translation).
Having hopefully clarified my position somewhat, I’ll move on to respond to some of the comments made in relation to my initial post.
Machine Translation is more accurate for language pairs other than English/Japanese
One of my main arguments against the use of MT is that it is simply inaccurate, and is more likely to produce word salad than grammatically correct sentences. Some commenters pointed out that Google Translate, and other MT tools, do much better for other language pairs, particularly the more syntactically and lexically related European languages.
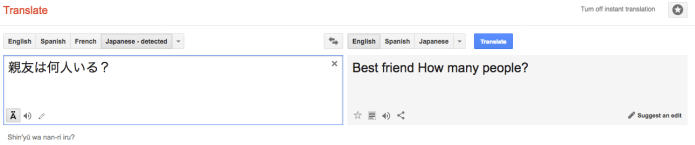
One of the sentences I used in my initial post was “How many close friends do you have?”. After feeding the natural Japanese translation for this sentence (親友は何人いる?) into Google Translate, it output “Best friend How many people”, which is a somewhat unsatisfactory result. However, repeating the same experiment with German (Wie viele enge Freunde haben Sie?) and Italian (Quante amiche intime hai?), Google managed to get the translation bang on, both times outputting “How many close friends do you have?”. However, it failed again for Arabic (How you have close friends?) and Russian (How do you close friends?).
“How many close friends do you have?” is a relatively short and simple sentence. How does MT perform with longer, more complex sentences or paragraphs?
I fed natural Japanese, French, and Italian translations of the following English paragraph into Google Translate:
One of the reasons Twitter is popular in Japan is a characteristic of Japanese itself: Japanese uses ideograms which enable it to convey more information in just 140 characters than other languages, not counting Chinese. Incidentally, the Japanese version of this sentence is written with exactly 140 characters. How many characters does it take in other languages?
For the Japanese translation, the tool output:
One of Twitter popularity of reason in Japan is on the characteristics of the language of Japanese. Japanese use ideographic characters, although not I the enemy is in Chinese, it is possible to incorporate a lot of content to 140 characters compared to many other languages. By the way, I wonder, but he has been written in Japanese version is just 140 characters of this sentence, become what characters in other languages?
For French:
One of the reasons that make the success of Twitter in Japan due to a peculiarity of the Japanese language. Compared to many other languages, Japanese, with its ideograms, can convey a lot of information in 140 characters, without competing with the Chinese. Incidentally, the Japanese version of the sentence is written in exactly 140 characters. But how many characters does it do so in other languages?
For Italian:
One of the reasons why Twitter is so popular in Japan is a very characteristic of the Japanese: Japanese uses ideograms that allow you to convey more information in 140 characters than other languages, without considering the Chinese. Inter-alia, the Japanese version of this sentence is written in exactly 140 characters. How many characters it wants in other languages?
Further research would be required to determine exactly how accurate MT is for any given language pair, but from these preliminary tests, it would seem that the less related the languages, the less accurate the translations. MT seems to do much better with more closely related language pairs, regardless of length or syntactical complexity.
The best approach to MT is not to ban it, but to highlight its (potential) inaccuracies. This is the correct approach regardless of the motivation or level of the students

In my initial post, I argued that it would be difficult to ban MT all together (although we could reduce the opportunity to use MT by eliminating coursework, for example). If we ban smart phones, on which students can covertly use MT, we completely discard the other more positive technological affordances they provide. Instead, I suggested that we could highlight its inaccuracies to more highly motivated students.
The reason why I restricted this approach to more “highly motivated” students is because they have a desire to improve their English accuracy and idiomaticity, whereas students with low motivation often simply want to meet the course requirements and receive a passing grade in the easiest possible way. Some unmotivated students see MT as a quick and easy way to produce the required written assignments by writing them entirely in L1 and letting MT do the rest.
If you allow or even endorse the use of MT, when it comes to grading submissions, what are you actually grading? When MT produces good results, the student may unjustly receive a good grade. When MT produces bad results, the teacher may waste their time giving corrections on English mistakes the student hasn’t even made! Although I’m sure the Google engineers would be grateful for the feedback.

Fully featured MT is not the same as pop-up translation
Some commenters highlighted the usefulness of websites such as Rikai.com, which provides automatic pop-up translations of words when a user hovers their mouse over them. There are many other tools offering similar functionality, including PopJisho, ReadLang, Rikai-chan for Firefox, Rikai-kun for Chrome, and my own Pop Translation tool. However, there is a substantive difference between these tools and fully featured MT such as Google Translate.
Pop-up translation tools provide definitions on a word-by-word basis, rather than attempting to translate whole sentences. Allowing students to use pop-up translation to read and understand a passage in English is different to allowing them to translate the whole passage into their L1, and perhaps not even read the English version. Pop-up translation cannot be used to unilaterally produce a complete English passage from the student’s L1, or produce an equivalent passage in the student’s L1 from English. When using pop-up translation to read an English passage, students still have to read the English passage to decipher its meaning. Pop-up translation simply provides a more convenient and powerful alternative to a traditional dictionary.
Concluding remarks
In the preliminary tests I conducted, MT performed much better when translating closely related languages, such as English and French, or English and Italian. It did much less well with English and Russian and English and Arabic. It did quite poorly for English and Japanese.
Fully featured MT, such as that provided by Google Translate, may not be helpful for language learning where students view the output as a replacement for their own work. In the case where a student writes an assignment in L1, pastes it into Google Translate, and submits the output without even reading it, it would be difficult to imagine that any language learning has taken place. The tool is not being used to assist learning, but rather to avoid learning.
Teachers who permit or endorse the use of MT for English written assignments run the risk of unfairly rewarding students where the MT produces good results, and wasting time giving feedback to students where MT produces bad results.
Finally, fully featured MT, such as Google Translate, must be distinguished from pop-up translation tools such as those provided by Rikai.com. Pop-up translation tools do not attempt to translate sentences or paragraphs, but merely provide a more powerful and convenient alternative to traditional dictionaries. It is hoped that they assist the learning of vocabulary in the sense that students will read the English passage, encounter a word or phrase they do not understand, see the pop-up translation, and apply the meaning to the English word in that particular context.